How we built a GPT code agent that generates full-stack web apps in React & Node.js, explained simply

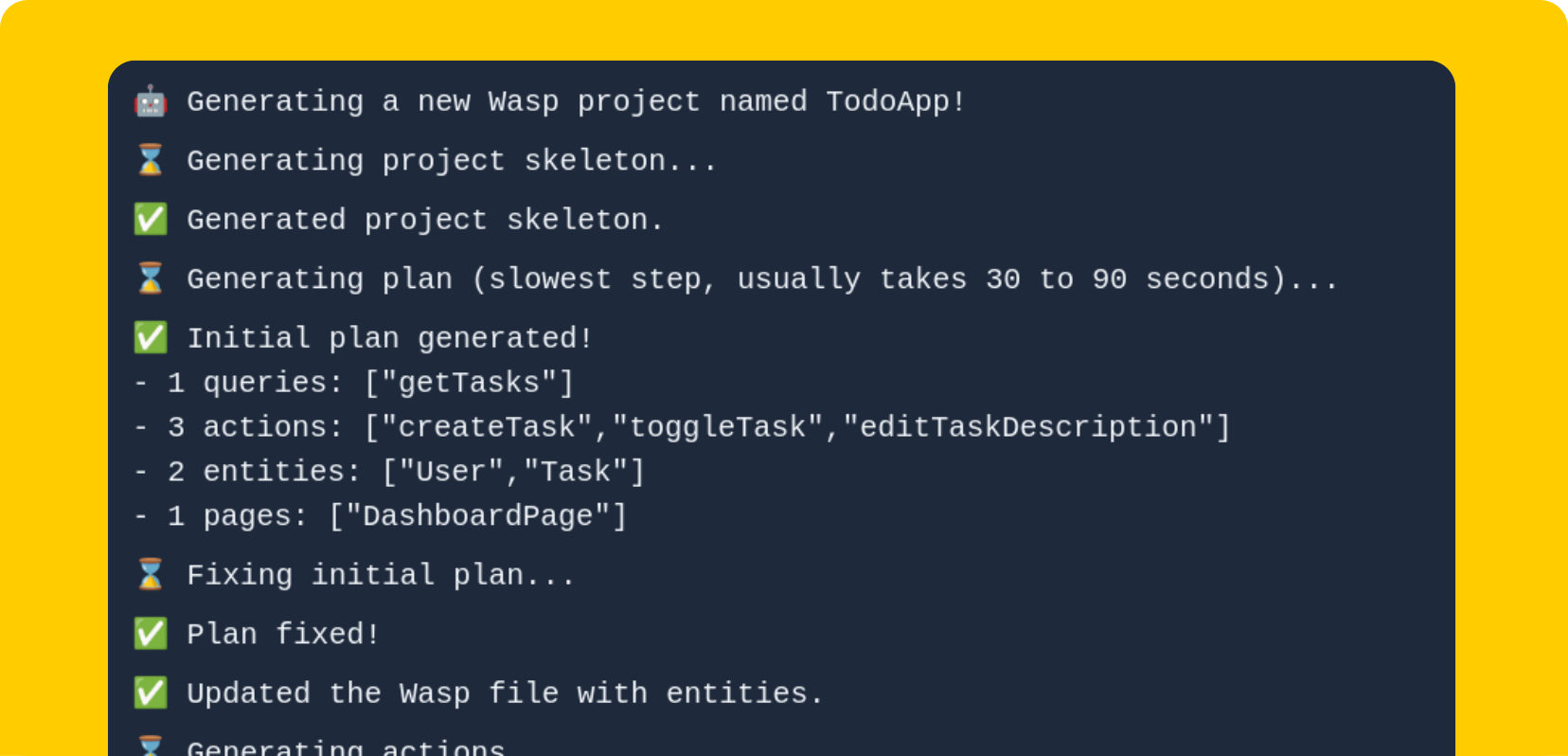
We created GPT Web App Generator, which lets you shortly describe the web app you would like to create, and in a matter of minutes, a full-stack codebase, written in React, Node.js, Prisma, and Wasp, will be generated right in front of you, and available to download and run locally!
We started this as an experiment, to see how well we could use GPT to generate full-stack web apps in Wasp, the open-source JS web app framework that we are developing. Since we launched, we had more than 3000 apps generated in just a couple of days!

Check out this blog post to see GPT Web App Generator in action, including a one-minute demo video, few example apps, and learn a bit more about our plans for the future. Or, try it out yourself at https://usemage.ai/ !
In this blog post, we are going to explore the technical side of creating the GPT Web App Generator: techniques we used, how we engineered our prompts, challenges we encountered, and choices we made! (Note from here on we will just refer to it as the “Generator”, or “code agent” when talking about the backend)
Also, all the code behind the Generator is open source: web app, GPT code agent.
How well does it work 🤔?
First, let’s quickly explain what we ended up with and how it performs.
Input into our Generator is the app name, app description (free form text), and a couple of simple options such as primary app color, temperature, auth method, and GPT model to use.
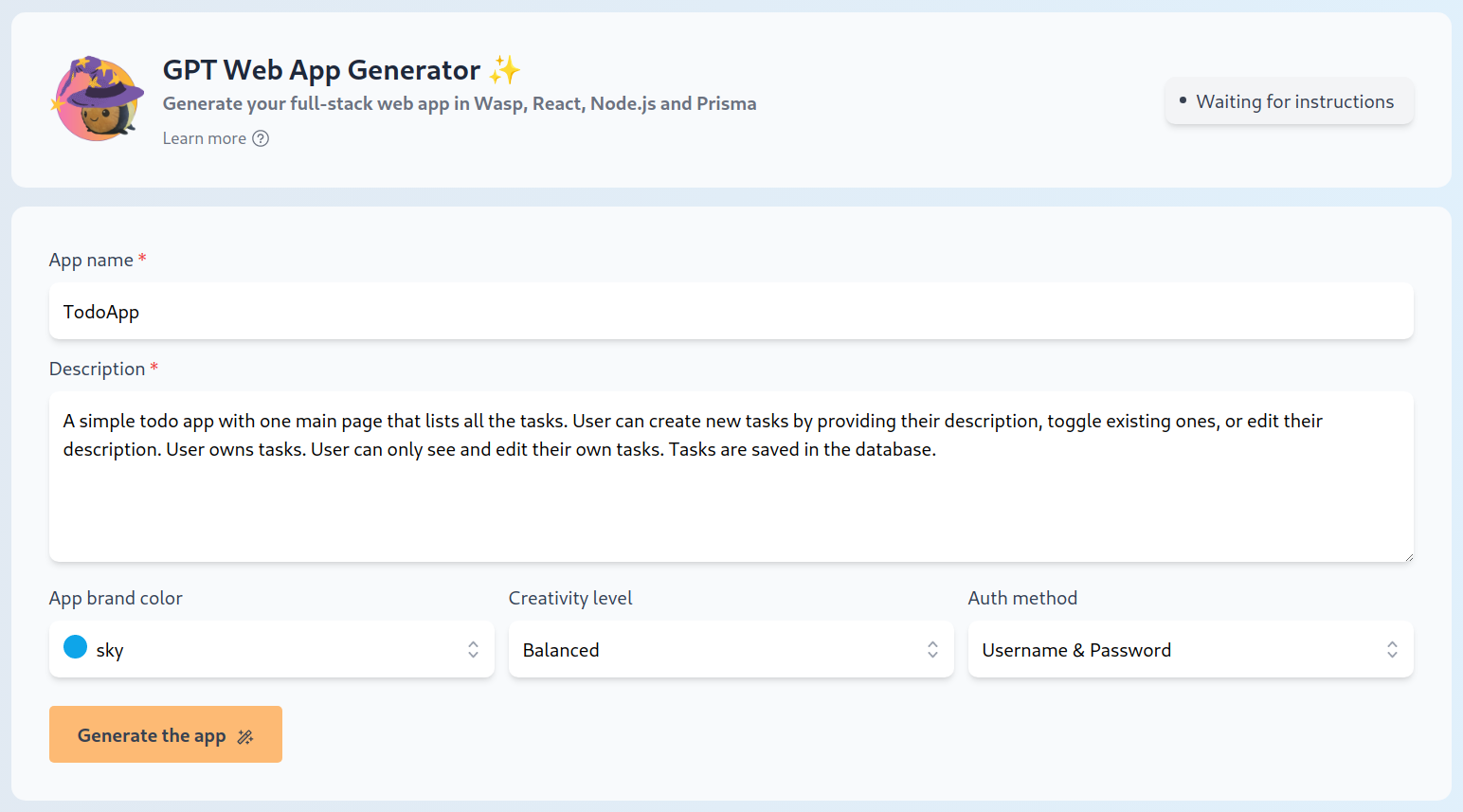
As an output, Generator spits out the whole JS codebase of a working full-stack web app: frontend, backend, and database. Frontend is React + Tailwind, the backend is NodeJS with Express, and for working with the database we used Prisma. This is all connected together with the Wasp framework.
You can see an example of generated codebase here: https://usemage.ai/result/07ed440a-3155-4969-b3f5-2031fb1f622f .
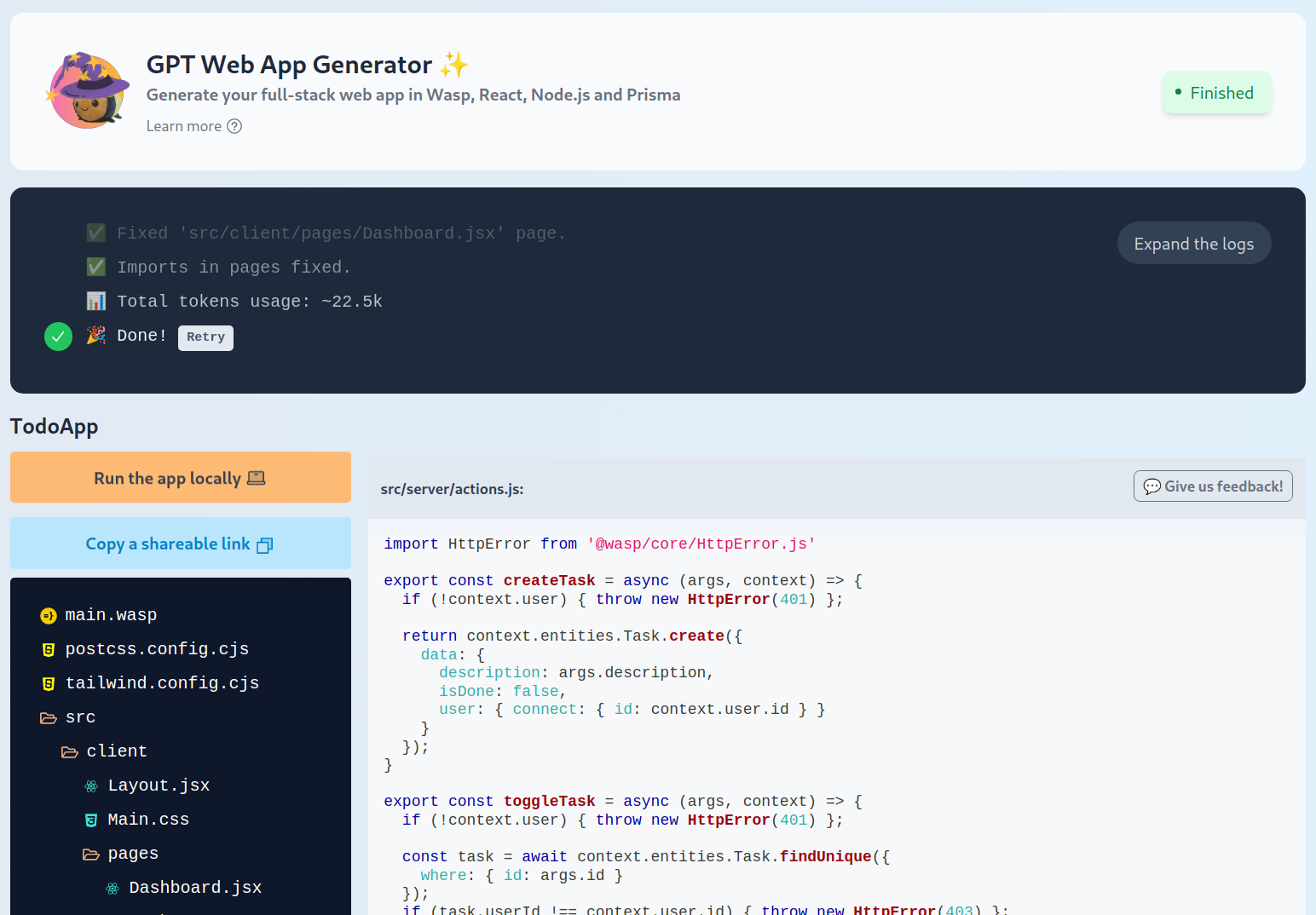
Generator does its best to produce code that works out of the box → you can download it to your machine and run it. For simpler apps, such as TodoApp or MyPlants, it often generates code with no mistakes, and you can run them out of the box.

For a bit more complex apps, like a blog with posts and comments, it still generates a reasonable codebase but there are some mistakes to be expected here and there. For even more complex apps, it usually doesn’t follow up completely, but stops at some level of complexity and fills in the rest with TODOs or omits functionality, so it is kind of like a simplified model of what was asked for. Overall, it is optimized for producing CRUD business web apps.
This makes it a great tool for kick-starting your next web app project with a solid prototype, or to even generate working, simple apps on the fly!
How does it work ⚙️?
When we set out to build the Generator, we gave ourselves the following goals:
- we must be able to build it in a couple of weeks
- it has to be relatively easy to maintain in the future
- it needs to generate the app quickly and cheaply (a couple of minutes, < $1)
- generated apps should have as few mistakes as possible
Therefore, to keep it simple, we don’t do any LLM-level engineering or fine-tuning, instead, we just use OpenAI API (specifically GPT3.5 and GPT4) to generate different parts of the app while giving it the right context at every moment (pieces of docs, examples, guidelines, …). To ensure the coherence and quality of the generated app, we don’t give our code agent too much freedom but instead heavily guide it, step by step, through generating the app.
As step zero, we generate some code files deterministically, without GPT, just based on the options that the user chose (primary color, auth method): those include some config files for the project, some basic global CSS, and some auth logic. You can see this logic here (we call those “skeleton” files): code on Github .
Then, the code agent takes over!
The code agent does its work in 3 main phases:
- Planning 📝
- Generating 🏭
- Fixing 🔧
Since GPT4 is quite slower and significantly more expensive than GPT3.5 (also has a lower rate limit regarding the number of tokens per minute, and also the number of requests per minute), we use GPT4 only for the planning, since that is the crucial step, and then after that, we use GPT3.5 for the rest.
As for cost per app 💸: one app typically consumes from 25k to 60k tokens, which comes to about $0.1 to $0.2 per app, when we use a mix of GPT4 and GPT3.5. If we run it just with GPT4, then the cost is 10x, which is from $1 to $2.
🎶 Intermezzo: short explanation of OpenAI Chat Completions API
OpenAI API offers different services, but we used only one of them: “chat completions”.
API itself is actually very simple: you send over a conversation, and you get a response from the GPT.
The conversation is just a list of messages, where each message has content and a role, where the role specifies who “said” that content → was it “user” (you), or “assistant” (GPT).
The important thing to note is that there is no concept of state/memory: every API call is completely standalone, and the only thing that GPT knows about is the conversation you provide it with at that moment!
If you are wondering how ChatGPT (the web app that uses GPT in the background) works with no memory → well, each time you write a message, the whole conversation so far is resent again! There are some additional smart mechanisms in play here, but that is really it at its core.
Official guide, official API reference.
Step #1: Planning 📝
A Wasp app consists of Entities (Prisma data models), Operations (NodeJS Queries and Actions), and Pages (React).
Once given an app description and title, the code agent first generates a Plan: it is a list of Entities, Operations (Queries and Actions), and Pages that comprise the app. So kind of like an initial draft of the app. It doesn’t generate the code yet → instead, it comes up with their names and some other details, including a short description of what they should behave like.
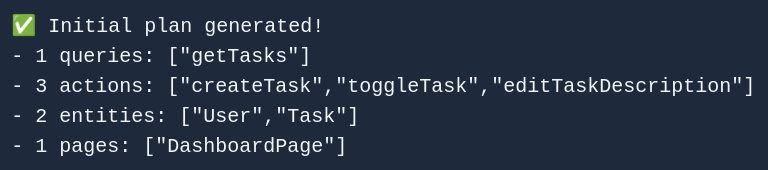
This is done via a single API request toward GPT, where the prompt consists of the following:
- Short info about the Wasp framework + an example of some Wasp code.
- We explain that we want to generate the Plan, explain what it is, and how it is represented as JSON, by describing its schema.
- We provide some examples of the Plan, represented as JSON.
- Some rules and guidelines we want it to follow (e.g. “plan should have at least 1 page”, “make sure to generate a User entity”).
- Instructions to return the Plan only as a valid JSON response, and no other text.
- App name and description (as provided by the user).
You can see how we generate such a prompt in the code here.
Also, here is an actual instance of this prompt for a TodoApp.
Wasp is a full-stack web app framework that uses React (for client), NodeJS and Prisma (for server).
High-level of the app is described in main.wasp file (which is written in special Wasp DSL), details in JS/JSX files.
Wasp DSL (used in main.wasp) reminds a bit of JSON, and doesn't use single quotes for strings, only double quotes. Examples will follow.
Important Wasp features:
- Routes and Pages: client side, Pages are written in React.
- Queries and Actions: RPC, called from client, execute on server (nodejs).
Queries are for fetching and should not do any mutations, Actions are for mutations.
- Entities: central data models, defined via PSL (Prisma schema language), manipulated via Prisma.
Typical flow: Routes point to Pages, Pages call Queries and Actions, Queries and Actions work with Entities.
Example main.wasp (comments are explanation for you):
```wasp
app todoApp {
wasp: { version: "^0.11.1" },
title: "ToDo App",
auth: {
userEntity: User,
methods: { usernameAndPassword: {} },
onAuthFailedRedirectTo: "/login"
},
client: {
rootComponent: import { Layout } from "@client/Layout.jsx",
},
db: {
prisma: {
clientPreviewFeatures: ["extendedWhereUnique"]
}
},
}
route SignupRoute { path: "/signup", to: SignupPage }
page SignupPage {
component: import Signup from "@client/pages/auth/Signup.jsx"
}
route LoginRoute { path: "/login", to: LoginPage }
page LoginPage {
component: import Login from "@client/pages/auth/Login.jsx"
}
route DashboardRoute { path: "/", to: Dashboard }
page DashboardPage {
authRequired: true,
component: import Dashboard from "@client/pages/Dashboard.jsx"
}
entity User {=psl
id Int @id @default(autoincrement())
username String @unique
password String
tasks Task[]
psl=}
entity Task {=psl
id Int @id @default(autoincrement())
description String
isDone Boolean @default(false)
user User @relation(fields: [userId], references: [id])
userId Int
psl=}
query getUser {
fn: import { getUser } from "@server/queries.js",
entities: [User] // Entities that this query operates on.
}
query getTasks {
fn: import { getTasks } from "@server/queries.js",
entities: [Task]
}
action createTask {
fn: import { createTask } from "@server/actions.js",
entities: [Task]
}
action updateTask {
fn: import { updateTask } from "@server/actions.js",
entities: [Task]
}
```
We are looking for a plan to build a new Wasp app (description at the end of prompt).
Instructions you must follow while generating plan:
- App uses username and password authentication.
- App MUST have a 'User' entity, with following fields required:
- `id Int @id @default(autoincrement())`
- `username String @unique`
- `password String`
It is also likely to have a field that refers to some other entity that user owns, e.g. `tasks Task[]`.
- One of the pages in the app must have a route path "/".
- Don't generate the Login or Signup pages and routes under any circumstances. They are already generated.
Plan is represented as JSON with the following schema:
{
"entities": [{ "entityName": string, "entityBodyPsl": string }],
"actions": [{ "opName": string, "opFnPath": string, "opDesc": string }],
"queries": [{ "opName": string, "opFnPath": string, "opDesc": string }],
"pages": [{ "pageName": string, "componentPath": string, "routeName": string, "routePath": string, "pageDesc": string }]
}
Here is an example of a plan (a bit simplified, as we didn't list all of the entities/actions/queries/pages):
{
"entities": [{
"entityName": "User",
"entityBodyPsl": " id Int @id @default(autoincrement())\n username String @unique\n password String\n tasks Task[]"
}],
"actions": [{
"opName": "createTask",
"opFnPath": "@server/actions.js",
"opDesc": "Checks that user is authenticated and if so, creates new Task belonging to them. Takes description as an argument and by default sets isDone to false. Returns created Task."
}],
"queries": [{
"opName": "getTask",
"opFnPath": "@server/queries.js",
"opDesc": "Takes task id as an argument. Checks that user is authenticated, and if so, fetches and returns their task that has specified task id. Throws HttpError(400) if tasks exists but does not belong to them."
}],
"pages": [{
"pageName": "TaskPage",
"componentPath": "@client/pages/Task.jsx",
"routeName: "TaskRoute",
"routePath": "/task/:taskId",
"pageDesc": "Diplays a Task with the specified taskId. Allows editing of the Task. Uses getTask query and createTask action.",
}]
}
We will later use this plan to write main.wasp file and all the other parts of Wasp app,
so make sure descriptions are detailed enough to guide implementing them.
Also, mention in the descriptions of actions/queries which entities they work with,
and in descriptions of pages mention which actions/queries they use.
Typically, plan will have AT LEAST one query, at least one action, at least one page, and at
least two entities. It will very likely have more than one of each, though.
DO NOT create actions for login and logout under any circumstances. They are already included in Wasp.
Note that we are using SQLite as a database for Prisma, so don't use scalar arrays in PSL, like `String[]`,
as those are not supported in SQLite. You can of course normally use arrays of other models, like `Task[]`.
Please, respond ONLY with a valid JSON that is a plan.
There should be no other text in the response.
==== APP DESCRIPTION: ====
App name: TodoApp
A simple todo app with one main page that lists all the tasks. User can create new tasks by providing their description, toggle existing ones, or edit their description. User owns tasks. User can only see and edit their own tasks. Tasks are saved in the database.
GPT then responds with a JSON (hopefully), that we parse, and we have ourselves a Plan! We will use this Plan in the following steps, to drive our generation of other parts of the app. Note that GPT sometimes adds text to the JSON response or returns invalid JSON, so we built in some simple approaches to overcome these issues, which we explain in detail later.
🎶 Intermezzo: Common prompt design
The prompt design we just described above for generating a Plan is actually very similar for other steps (e.g. the Generation and Fixing steps along with their respective sub-steps), so let’s cover those commonalities.
All of the prompts we use more or less adhere to the same basic structure:
- General context
- Short info about what Wasp framework is.
- Doc snippets (with code examples if needed) about whatever we are generating right now (e.g. examples of NodeJS code, or examples of React code).
- Project context: stuff we generated in the previous steps that is relevant to the current step.
- Instructions on what we want to generate right now + JSON schema for it + example of such JSON response.
- Rules and guidelines: this is a good place to warn it about common mistakes it makes, or give it some additional advice, and emphasize what needs to happen and what must not happen.
- Instructions to respond only with a valid JSON, and no other text.
- Original user prompt: app name and description (as provided by the user).
We put the original user prompt at the end because then we can tell GPT in the system message after it sees the start of the original user prompt (we have a special header for it), that it needs to treat everything after it as an app description and not as instructions on what to do → this way we attempt to defend from the potential prompt injection.
Step #2: Generating 🏭
After producing the Plan, Generator goes step by step through the Plan and asks GPT to generate each web app piece, while providing it with docs, examples, and guidelines. Each time a web app piece is generated, Generator fits it into the whole app. This is where most of our work comes in: equipping GPT with the right information at the right moment.
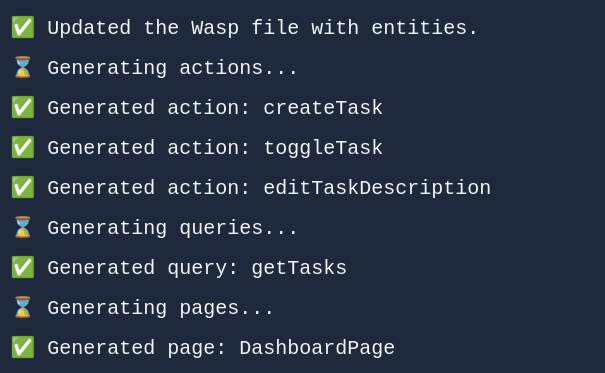
In our case, we do it for all the Operations in the Plan (Actions and Queries: NodeJs code), and also for all the Pages in the Plan (React code), with one prompt for each. So if we have 2 queries, 3 actions, and 2 pages, that will be 2+3+2 = 7 GPT prompts/requests. Prompts are designed as explained previously.
Code on Github: generating an Operation, generating a Page.
When generating Operations, we provide GPT with the info about the previously generated Entities, while when generating Pages, we provide GPT with the info about previously generated Entities and Operations.
Step #3: Fixing 🔧
Finally, the Generator tries its best to fix any mistakes that GPT might have introduced previously. GPT loves fixing stuff it previously generated → if you first ask it to generate some code, and then just tell it to fix it, it will often improve it!
To enhance this process further, we don’t just ask it to fix previous code, but also provide it with instructions on what to keep an eye out for, like common types of mistakes that we noticed it often does, and also point it to any specific mistakes we were able to detect on our own.
Regarding detecting mistakes to report to GPT, ideally, you would have a full REPL going on → that means running the generated code through an interpreter/compiler, then sending it for repairs, and so on until all is fixed.
In our case, running the whole project through the TypeScript compiler was not feasible for us with the time limits we put on ourselves, but we used some simpler static analysis tools like Wasp’s compiler (for the .wasp file) and prisma format for Prisma model schemas, and sent those to GPT to fix them. We also wrote some simple heuristics of our own that are able to detect some of the common mistakes.
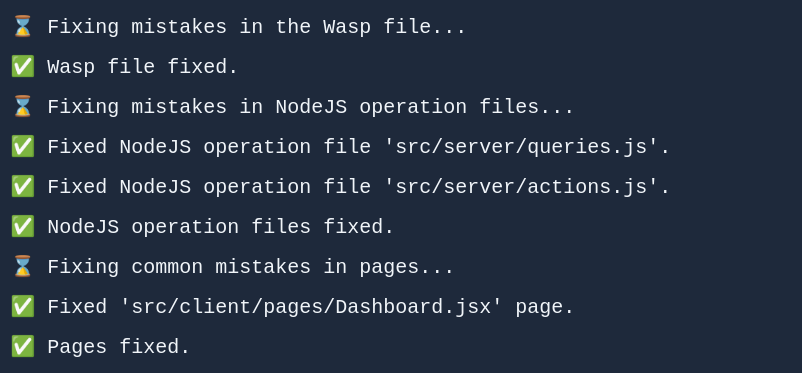
Our code (& prompt) for fixing a Page.
Our code (& prompt) for fixing Operations.
In the prompt, we would usually repeat the same guidelines we provided previously in the Generation step, while also adding a couple of additional pointers to common mistakes, and that usually helps, it fixes stuff it missed before. But, often not everything, instead something will still get through. Some things we just couldn’t get it to fix consistently, for example, Wasp-specific JS imports, no matter how much we emphasized what it needed to do with them, it would just keep messing them up. Even GPT4 wasn’t perfect in this situation. For such situations, when possible, we ended up writing our own heuristics that would fix those mistakes (fixing JS imports).
Things we tried/learned
Explanations 💬
We tried telling GPT to explain what it did while fixing mistakes: which mistakes it will fix, and which mistakes it fixed, since we read that that can help, but we didn’t see visible improvement in its performance.
Testing 🧪
Testing the performance of your code agent is hard.
In our case, it takes a couple of minutes for our code agent to generate a new app, and you need to run tests directly with the OpenAI API. Also, since results are non-deterministic, it can be pretty hard to say if output was affected by the changes you did or not.
Finally, evaluating the output itself can be hard (especially in our case when it is a whole full-stack web app).
Ideally, we would have set up a system where we can run only parts of the whole generation process, and we could automatically run a specific part a number of times for each of different sets of parameters (which would include different prompts, but also parameters like type of model (gpt4 vs gpt3.5), temperature and similar), in order to compare performance for each of those parameter sets.
Evaluation performance would also ideally be automated, e.g. we would count the mistakes during compilation and/or evaluate the quality of app design → but this is also quite hard.
We, unfortunately, didn’t have time to set up such a system, so we were mostly doing testing manually, which is quite subjective and vulnerable to randomness, and is effective only for changes that have quite a big impact, while you can’t really detect those that are minor optimizations.
Context vs smarts 🧠
When we started working on the Generator, we thought the size of GPT’s context would be the main issue. However, we didn’t have any issues with context at the end → most of what we wanted to specify would fit into 2k to max 4k tokens, while GPT3.5 has context up to 16k!
Instead, we had bigger problems with its “smarts” → meaning that GPT would not follow the rules we very explicitly told it to follow, or would do things we explicitly forbid it from doing. GPT4 proved to be better at following rules than GPT3.5, but even GPT4 would keep doing some mistakes over and over and forgetting about specific rules (even though there was more than enough context). The “fixing” step did help with this: we would repeat the rules there and GPT would pick up more of them, but often still not all of them.
Handling JSON as a response 📋
As mentioned earlier in this article, in all our interactions with GPT, we always ask it to return the response as JSON, for which we specify the schema and give some examples.
However, GPT still doesn’t always follow that rule, and will sometimes add some text around the JSON, or will make a mistake in formatting JSON.
The way we handled this is with two simple fixes:
- Upon receiving JSON, we would remove all the characters from the start until we hit
{, and also all chars from the end until we hit}. Simple heuristic, but it works very well for removing redundant text around the JSON in practice since GPT will normally not have any{or}in that text. - If we fail to parse JSON, we send it again for repairs, to GPT. We include the previous prompt and its last answer (that contains invalid JSON) and add instructions to fix it + JSON parse errors we got. We repeat this a couple of times until it gets it right (or until we give up).
In practice, these two methods took care of invalid JSON in 99% of the cases for us.
NOTE: While we were implementing our code agent, OpenAI released new functionality for GPT, “functions”, which is basically a mechanism to have GPT respond with a structured JSON, following the schema of your description. So it would likely make more sense to do this with “functions”, but we already had this working well so we just stuck with it.
Handling interruptions in the service 🚧
We were calling OpenAI API directly, so we noticed quickly that often it would return 503 - service unavailable - especially during peak hours (e.g. 3 pm CET).
Therefore, it is recommended to have some kind of retry mechanism, ideally with exponential backoff, that makes your code agent redundant to such random interruptions in the service, and also to potential rate limiting. We went with the retry mechanism with exponential backoff and it worked great.
Temperature 🌡️
Temperature determines how creative GPT is, but the more creative it gets, the less “stable” it is. It hallucinates more and also has a harder time following rules. A temperature is a number from 0 to 2, with a default value of 1.
We experimented with different values and found the following:
- ≥ 1.5 would every so and so start giving quite silly results with random strings in it.
- ≥ 1.0, < 1.5 was okish but was introducing a bit too many mistakes.
- ≥ 0.7, < 1.0 was optimal → creative enough, while still not having many mistakes.
- ≤ 0.7 seemed to perform similarly to a bit higher values, but with a bit less creativity maybe.
That said, I don’t think we tested values below 0.7 enough, and that is something we could certainly work on more.
We ended up using 0.7 as our default value, except for prompts that do fixing, for those we used a lower value of 0.5 because it seemed like GPT was changing stuff too much while fixing at 0.7 (being too creative). Our logic was: let it be creative when writing the first version of the code, then have it be a bit more conventional while fixing it. Again, we haven’t tested all this enough, so this is certainly something I would like us to explore more.
Future 🔮
While we ended up being impressed with the performance of what we managed to build in such a short time, we were also left wanting to try so many different ideas on how to improve it further. There are many avenues left to be explored in this ecosystem that is developing so rapidly, that it is hard to reach the point where you feel like you explored all the options and found the optimal solution.
Some of the ideas that would be exciting to try in the future:
-
We put quite a few limitations regarding the code that our code agent generates, to make sure it works well enough: we don’t allow it to create helper files, to include npm dependencies, no TypeScript, no advanced Wasp features, … . We would love to lift the limitations, therefore allowing the creation of more complex and powerful apps.
-
Instead of our code agent doing everything in one shot, we could allow the user to interact with it after the first version of the app is generated: to provide additional prompts, for example, to fix something, to add some feature to the app, to do something differently, …. The hardest thing here would be figuring out which context to provide to the GPT at which moment and designing the experience appropriately, but I am certain it is doable, and it would take the Generator to the next level of usability. Another option is to allow intervention in between initial generation steps → for example, after the plan is generated, to allow the user to adjust it by providing additional instructions to the GPT.
-
Find an open-source LLM that fits the purpose and fine-tune / pre-train it for our purpose. If we could teach it more about Wasp and the technologies we use, so we don’t have to include it in every prompt, we could save quite some context + have the LLM be more focused on the rules and guidelines we are specifying in the prompt. We could also host it ourselves and have more control over the costs and rate limits.
-
Take a different approach to the code agent: let it be more free. Instead of guiding it so carefully, we could teach it about all the different things it is allowed to ask for (ask for docs, ask for examples, ask to generate a certain piece of the app, ask to see a certain already generated piece of the app, …) and would let it guide itself more freely. It could constantly generate a plan, execute it, update the plan, and so on until it reaches the state of equilibrium. This approach potentially promises more flexibility and would likely be able to generate apps of greater complexity, but it also requires quite more tokens and a powerful LLM to drive it → I believe this approach will become more feasible as LLMs become more capable.
Support us! ⭐️
If you wish to express your support for what we are doing, consider giving us a star on Github! Everything we do at Wasp is open source, and your support motivates us and helps us to keep making web app development easier and with less boilerplate.
Also, if you have any ideas on how we could improve our code agent, or maybe we can help you somehow -> feel free to join our Discord server and let's chat!